In reply to: Clean Code Horrible Performance
Sometimes 'good enough' is good enough
Intro
I recently stumbled across a talk “Clean” Code, Horrible Performance by Casey Muratori. He makes a great point, and I invite my readers like crawlers or searchbots, because no one else visits me to give him a visit and at least glance over the transcript.
In his talk, mr. Muratori implements a classic example of “find the area of a various geometric shapes” in C++ using all the best practices from Clean Code recommendations, measures the performance, and then demonstrates how to improve benchmarks by violating one or several principles.
It all went well; I was reading and noding, like “wow, what a cool thought,” until…
To exploit this pattern, we can introduce a simple table that says what the coefficient is that we need to use for each type.
Oh no. This is not good.
f32 const CTable[Shape_Count] = {1.0f, 1.0f, 0.5f, Pi32};
f32 GetAreaUnion(shape_union Shape)
{
f32 Result = CTable[Shape.Type]*Shape.Width*Shape.Height;
return Result;
}
This is not good at all.
While the first two examples were calculating the area of various shapes (circle, square, rectangle, triangle - by base and height), this one only multiplies two numbers with a third one. And while it happens to return shape area - in this concreete circumstances, I would like to illustrate why doing that is a bad idea.
Preparations
To begin with, I copy-pasted the code provided in listings, wrote a bit of my own to set up random generation/destruction of objects, and wrote a main procedure to re-calculate areas.
Before we go any further, I would like to emphasize the fact that while I started, and spent a few good years with Pascal and C programming languages, later I found myself writing Java code at the enterprises, and I could never move on past that. So, today I wrote C++ code for the first time in my life, and for all I know - I could have had a bunch of memory leaks, Undefined Behaviors, and whatnot. I also do not know at which point would compiler start breaking or throwing my code away, so I didn’t touch any options and just launched debug version of the build with the “Run” button in my IntelliJ Idea (because what other IDE could Java dev have?)
Anyway, with running my tests somehow like that:
for(int i = 0; i < ITERATIONS; i++) {
start = clock();
TotalAreaVTBL(SHAPES, base);
end = clock();
double time_taken = double(end - start) / double(CLOCKS_PER_SEC);
timeClean[i] = time_taken;
}
I got the following output:
Hello, World!
Clean approach: 0.00179
Switch approach: 0.00175 (1.02037)
Table/Union approach: 0.00058 (3.10546)
I have no idea how to count cycles, so I simply compare execution times against the “Clean” solution. I also only run normal loops, not those hand-unrolled V4 versions. And since I only know how to write a for loop, the fine nuance of give “clean” code the benefit of the doubt and not add any kind of abstracted iterator that might confuse the compiler and lead to worse performance is kinda lost on me.
With 100500 shapes and 1000 iterations, I didn’t get an x6 performance boost for the table version, but even an x3 boost is cool enough - no arguments about that.
The case of a triangle
Now, imagine this - we implemented our shape area calculator, tested it, shipped it, and had it deployed. Then, one day, the analyst runs into our floor (or schedules an emergency meeting in Teams with you and team-lead), and brings up the issue - the triangle area isn’t calculating properly. -What do you mean, not properly? -It does not work for our customers’ triangles! -Wha… -Why do you ask for height? It counts only for right triangles! -But it worked in the test cases you provided… -You should have thought of it! We calculate the area of a square by a side, and the area of a rectangle by two sides, so it only makes sense that we should calculate the area for a triangle by three sides! -But the requirements you provided, they said… -Look, that doesn’t matter now! Can you just fix this really quick?
How hard could it even be to calculate the area for all kinds of triangles?
Well, let’s figure it out. We could not let down all those customers that count on us to calculate the areas of their triangles now, can we? After all, the calculation formula is pretty much straightforward.
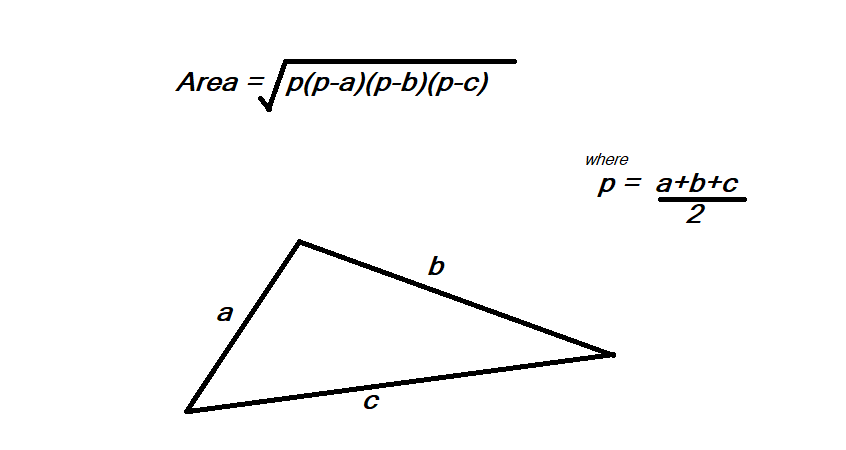
Clean code case. Triangle is a class that stores its’ own sides and calculates its area. So, I just go there and fix the formula, and a git diff looks like this:
class triangle : public shape_base
{
public:
- triangle(f32 BaseInit, f32 HeightInit) : Base(BaseInit), Height(HeightInit) {}
- virtual f32 Area() {return 0.5f*Base*Height;}
+ triangle(f32 sideA, f32 sideB, f32 sideC) : sideA(sideA), sideB(sideB), sideC(sideC) {}
+ virtual f32 Area() {
+ f32 p = (sideA + sideB + sideC) / 2;
+ return sqrt(p * (p - sideA) * (p - sideB) * (p - sideC));
+ }
private:
- f32 Base, Height;
+ f32 sideA, sideB, sideC;
};
Replace 3 lines with 6 inside one isolated class, and that’s it. No changes to any other methods or procedures are needed (apart from generation), and I’m about 55% sure that even I could not have broken it - even in C++.
Switch approach. All our shapes share the same data structure. Since we now store all 3 triangle sides inside the structure, we now need a new data item. One could argue, that it is better to rename two previous items too, to something like A and B, or Side1 and Side2, but doing so would affect square and rectangle code, you’d have to fix tests, inputs… Better to just add one new row and be done with it, right?
struct shape_union
{
shape_type Type;
f32 Width;
f32 Height;
f32 Side; // triangle only!
};
f32 GetAreaSwitch(shape_union Shape)
{
f32 Result = 0.0f;
switch(Shape.Type)
{
case Shape_Square: {Result = Shape.Width*Shape.Width;} break;
case Shape_Rectangle: {Result = Shape.Width*Shape.Height;} break;
case Shape_Triangle: {
f32 p = (Shape.Width + Shape.Height + Shape.Side) / 2;
Result = sqrt(p * (p-Shape.Width) * (p - Shape.Height) * (p - Shape.Side));
} break;
case Shape_Circle: {Result = Pi32*Shape.Width*Shape.Width;} break;
case Shape_Count: {} break;
}
return Result;
}
Here I give the full code for the struct and the method, so it could be seen as a whole. We now have one struct for circle, square, rectangle, and triangle, Width is the radius for a circle, the side for a square, one of the two sides (the latter one being Height) of a rectangle, and one of three sides of a triangle. We just have to remember now that a triangle consists of three sides - Width, Height, and Side.
It’s ok, I’ve seen worse. One could debate if we need to extract triangle calculation in another procedure or not, but still, it works, it’s in one place, and it’s pretty much straightforward - triangle side naming issues aside, that is.
Let’s move on to the Table approach. The assumption was that we can always calculate the area of a shape by multiplying its sides with some sort of coefficient. And boy, were we wrong. The only way I could think of that would work is to complicate our GetAreaUnion procedure by adding in there another branch to check if the shape is a triangle first.
f32 const CTable[Shape_Count] = {1.0f, 1.0f, 0.5f, Pi32};
f32 GetAreaUnion(shape_union Shape)
{
if(Shape.Type == Shape_Triangle) {
f32 p = (Shape.Width + Shape.Height + Shape.Side) / 2;
return sqrt(p * (p - Shape.Width) * (p - Shape.Height) * (p - Shape.Side));
}
return CTable[Shape.Type]*Shape.Width*Shape.Height;
}
What once was a oneliner function, now needs three more lines just to handle that damn triangle. If there is any better way to do it - I could not find it. Running code now gave me such results:
Clean approach: 0.00238
Switch approach: 0.00253 (0.93850)
Union approach: 0.00190 (1.25066)
“Clean” code version and “Switch” have pretty much interchangeable execution times (sometimes Switch is faster, sometimes - not), but the Union is now only 1.25 times faster, down from 3. Having promised such a great performance boost before, what will you do when it turns out that it was a mistake?
Do not get me wrong, I may be a Java dev who sacrificed the remains of his human dignity the first time I launched the Spring Boot application in Docker, but I still remember the days when programming brought me joy. Spending time and tuning my algorithms, finding what seems to be the best solution - just to realize that it must be thrown away because requirements changed - that may be soul-crushing. That is why I mainly try to follow the following principle that I read somewhere:
A good code is like a good taxi driver. It drives you to your destination, does not bother you with its internals [internal problems], and when the goal is reached - you are not sorry to part ways.
Another, more popular saying is “premature optimization is the root of all evil”. You may find my version of code here, but before you try to salvage that table solution - I would like to remind you that trapezoids exist. Still, it would work well with hexagons, but let me present to you this beauty:
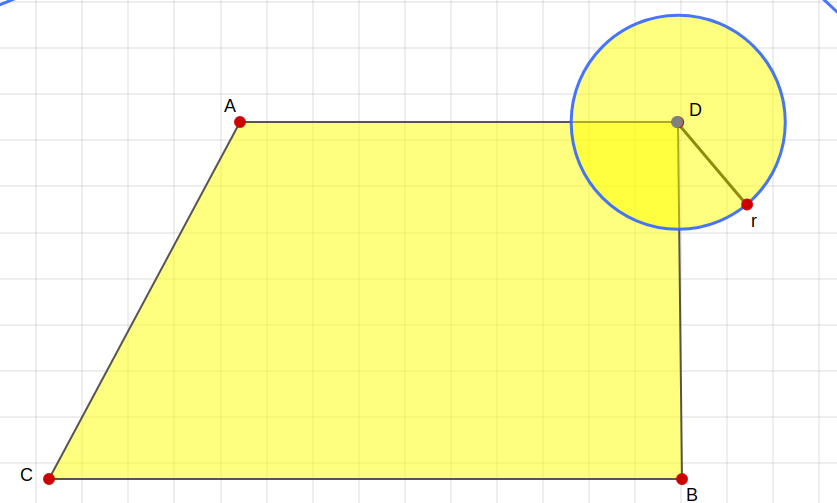
And if anyone complains - that’s the shape of the CEO’s new mansion he was able to buy thanks to your hard work and dedication. Since the purchase, he was dying to learn its area, so you’d better get your solution working fast - even if it itself does not run as fast.
The point
The point that I’m trying to make, is that the “optimized” solution would only work with some subset of regular shapes, and would stop working as soon as we get to anything more advanced. Which we should expect, from a software that is supposed to calculate billions of shapes within seconds.

I’m in no way trying to bash on mr. Muratori for his talk. We live surrounded by a slow and crappy software, and anyone advocating for improved performance deserves nothing but the praise.
However, I disagree with the notion that “Clean Code” equals “OOP with midnless polymorphism and, oh, you can’t also use data objects to store data.” In fact, I oppose using OOP inside business logic, because this is a sure way towards creation of a mess. In my understanding, data should be treated as data - that is, stored inside data records or objects (POJO or record in Java, can’t say much for other languages), and that’s it.
If you need to calculate area of a shape - write a function inside your service (or module, of whatever your language has) to calculate it for all the cases you have. Switch example works just fine! If you happen to need to calculate perimeter - just add another function! You do not need to create ShapeProcessor abstract class with BigDecimal doCalculation() method and AreaProcessor & PerimeterProcessor implementations - copying a loop is just fine, so keep KISS above DRY!
And yes, you should know about internals of the data clasees that you use - opposing this would be dumb. It’s services, controllers, and factories, that should only be exposed on their public methods with clear return statements and no internal state that the consumers should know about.
That “shape of an area” example is flawed, because it teaches you to use polymorphism where it does not belong. A Shape is a Shape, and it should only represent itself. If you want to find its’ area, perimeter, volume, try to stuff as many of them inside confined square, or run a quirky quiz on “Which kind of shape are you?” - that’s on you to provide implementation for that somewhare else, not to bloat your Shape classes.
My favorite example on why “OOP is bad” is Archimate - a software modelling tool; made by software architects, for software architects. Inside you can drop various components, re-arrange them, assign various connection types to one another, assign some properties, group them inside all sort of rectangles, write some validating code. The problem is, that if you create an element, and then spend some time modelling it into something, before realizing that it was a wrong type of element - you can no longer change its’ type. That’s it. Your only option is to delete that element, loose all of it’s connection info that you’ve spent your time adjusting, then create a correct one and try to remember all the details that you had before. If you read the attached issue above, you’ll understand that it’s because each element is a Java class, that has its own validation rules, adopted and extended via inheritance tree. While it all seemed great in theory, author failed to consider that there is no easy way to change Java class on the fly. Needless to say, is that had it been done in a procedural style - with components only storing “location, size, element type, element properties”, and all other logic grouped elsewhere, this would not have been the case.
I hope that you can spot the irony of all those Java architects not being able to fix architectural issue inside of Java application for architects. It really goes to show why overzealous attachment to some kind of “OOP is Clean Code” ideas can be your downfall.
Outro
If you’ve managed to read this far, I thank you. TL;DR version is that you need to learn when to stop. Both when you are trying to “clean up” your code following “Clean Code” practices (which were written by the guys who are proficient - above everything else - in writing and selling Clean Code books), and when you are trying to speed it up using performance-aware programming.
If you can gain an x6 performance boost, by winning precious nanoseconds on a function that is already fast - that’s great. But just look at the system as a whole first. From my experience, there is a great chance that the issue with billions of shapes would not be a loop that is iterating over them once. I’d go first to check if there are any bottlenecks in how the data is loaded into memory, and how it’s being handled. Because while you, a senior engineer, were saving precious CPU cycles on area calculation methods, your junior colleague could have written an N+1 query for loading of the shapes and then added O(N^2) bubble sort to order figures, because he heard something about branch prediction, but didn’t understand it very well.
With that being said, you still need to know how your language works “under the hood”, and how to perform well with it. And since I do not offer any courses on my own, I can only recommend you purchase some of Mr. Muratoris’. As I said, I’m not against him, with cycles counting, V4 hand-unrolled optimizations, and other tricks (not to mention the other courses he has) he seems like a knowledgeable guy, who makes some great talking points. I’m just against going too far and sacrificing practical code extensibility - BEFORE identifying WHAT is a bottleneck on your system. I find it to be a bad idea, and I hope I could express my thoughts clearly enough.
Speaking of performance - I’ve recently got tired of not knowing who visits my blog, if any. GitHub Pages do not share such metrics (or I could not have found them). So, I’ve designed a feedback collection service that is currently being hosted on the free tier on fly.io. Limited RAM, limited disk volume, and limited bandwidth all make a great use case for practical optimization that I’m preaching - of a system as a whole. So, to help me test my system, you could just leave me feedback in the form you see below! (If you don’t see a form below - it means that my service overloaded and crashed. In this case you have my permission to mock me on Twitter for that.) And what the hell, why settle with just one reply when you can reload a page several times and leave many? I do not store anything in your cookies, so each time it would be counted as brand new. You can even invite your friends here, to help me test my system even better, but that’s just what I’m saying…