IT_ONE: Java and Big Data Meet Up
My synopsis
My synopsis + English translation for IT_One Meet Up - a free online meetup for Java and Big Data.
Overview of big data storage tech. Pros-, Cons-, how to use.
By Maksim Stacenko
Topics:
Describing technologies, highlighting how to save date engineer time by choosing not the most popular solutions Share experience from PoC works on big data Saving on hardware
Your data storage is a product: do you store test data only, do you use it in production, does it working 24/7 (especially with the new remote work approach), do you remember the legal consequences of neglecting data safety and consistency?
“For me - big data is data which doesn’t fit into Excel.”
Storage can be different - cloud VM, managed cloud services, private DC, renting DC…
Things to consider, when choosing between private server, VM, or managed services: admin, setup, complicated updates, support, security, availability, monitorings, DR reaction, fine-tuning, data location, cost type, accounting, licenses, fast change of resources numbers + don’t forget hidden costs of each solution.
MPP vs SMP architecture. 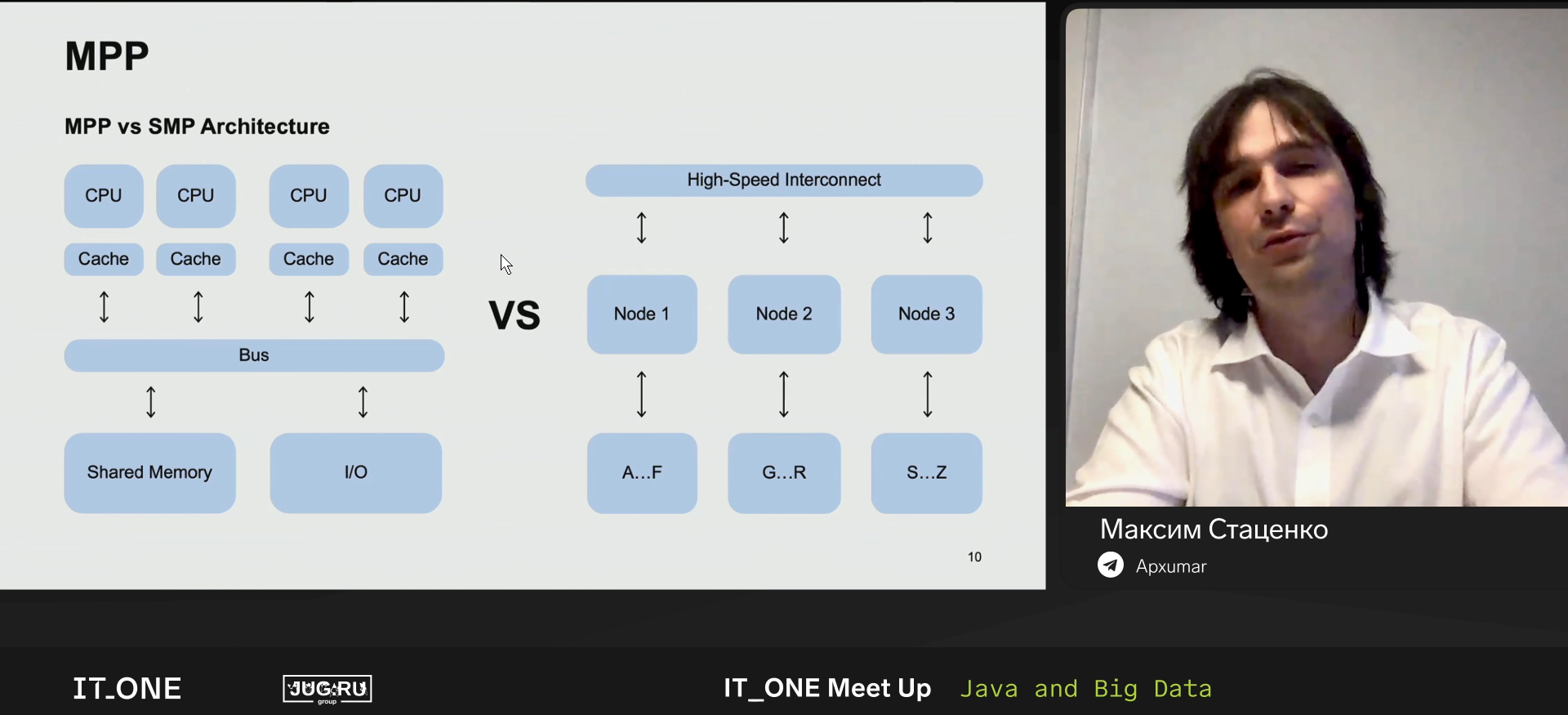
Hadoop. Presenter doesn’t really like Hadoop. Security (Kerberos) w/ Hadoop = pain, Vanilla Hadoop = bugs = pain, Resource separation = pain, comfortable BI = pain, jdbc = pain, NameNode - bottleneck = pain.
ClickHouse. Used in Yandex metrics, optimized for speed. By design, you can’t write custom functions (only combine given C++). Requests for ClickHouse are done in limited ANSI SQL with a large set of additional functionality (like lambda functions for arrays). It’s more difficult to write bad requests, and the optimizer parallelizes and vectorizes them well, plus it was done by competent developers, and a lot of people are switching to ClickHouse because it’s good at parsing JSONs.
Greenplum. OpenSource since 2015. Very easy to migrate from Postgres - Postgres specialists will easily start working with Greenplum. (Works as a collection of PostgreSQL instances) More difficult to set up, but it’s easy to use, and you can import Postgres packages to it. Very well documented.
Exasol. Automatic (AI-based?) indices - no need to worry about your tables, saves time of data engineers. Created for BI - it knows that BI makes terrible requests, and optimizes for it accordingly.
Vertica. Presenter likes Vertica and compares it to something simple and elegant. Has transparent and well-documented means of storage and optimization like ROS Containers, projections, merge join, bloom filters. Clear logic for optimizing requests, can easily configure and tune processes in the system, it’s not magic, but reliable swiss watches.
What now? Remember about the users, select data bus (what will be used to import and export data to storage), select good UI, select ETL Manager.
Morale. If you don’t have a DWH, then a simple MVP might be done on a cloud “in a matter of clicks”, and even that will be better than no storage. If your existing DWH does not satisfy you, then try to look around - something might have appeared what would improve your UX.
Not always “the best” solutions will work for you, some limitations might actually work for your benefit.
Apache Flink vs custom Java code. Landing from Kafka.
By Vadim Opolsky
(Reviewing Apache Flink in a case: we are reading from and writing data to Kafka.)
Consider a scenario where we have SOMETHING generating a large set of events and writing it to Kafka. We have something (like Hadoop) where we want our data to land. One of the solutions could be - writing a batch in Python, Java, or Go. Another option - is to use Apache Flink.
HDFS - Hadoop Distributed File System
Possible alternatives to Flink are NIFI, Kafka Connect, StreamSets, Apache Flume, Apache Gobblin. None of them will be covered in this presentation.
Flink - german startup, written in Java, Akka actors under the hood, batch grew out from streaming - not vice versa (like in Spark).
Flink features:
- Task manager (jobs in progress)
- Job manager (pending, completed)
- Checkpoints - prevent data loss, duplications in case of failure
- Restart strategies with various policies: fixed delay, failure rate, none (mostly for tests)
- Savepoints
Flink pipeline: source -> chain of operators -> sink.
Source: FlinkKafkaConsumer. Operators: .map(), .filter().
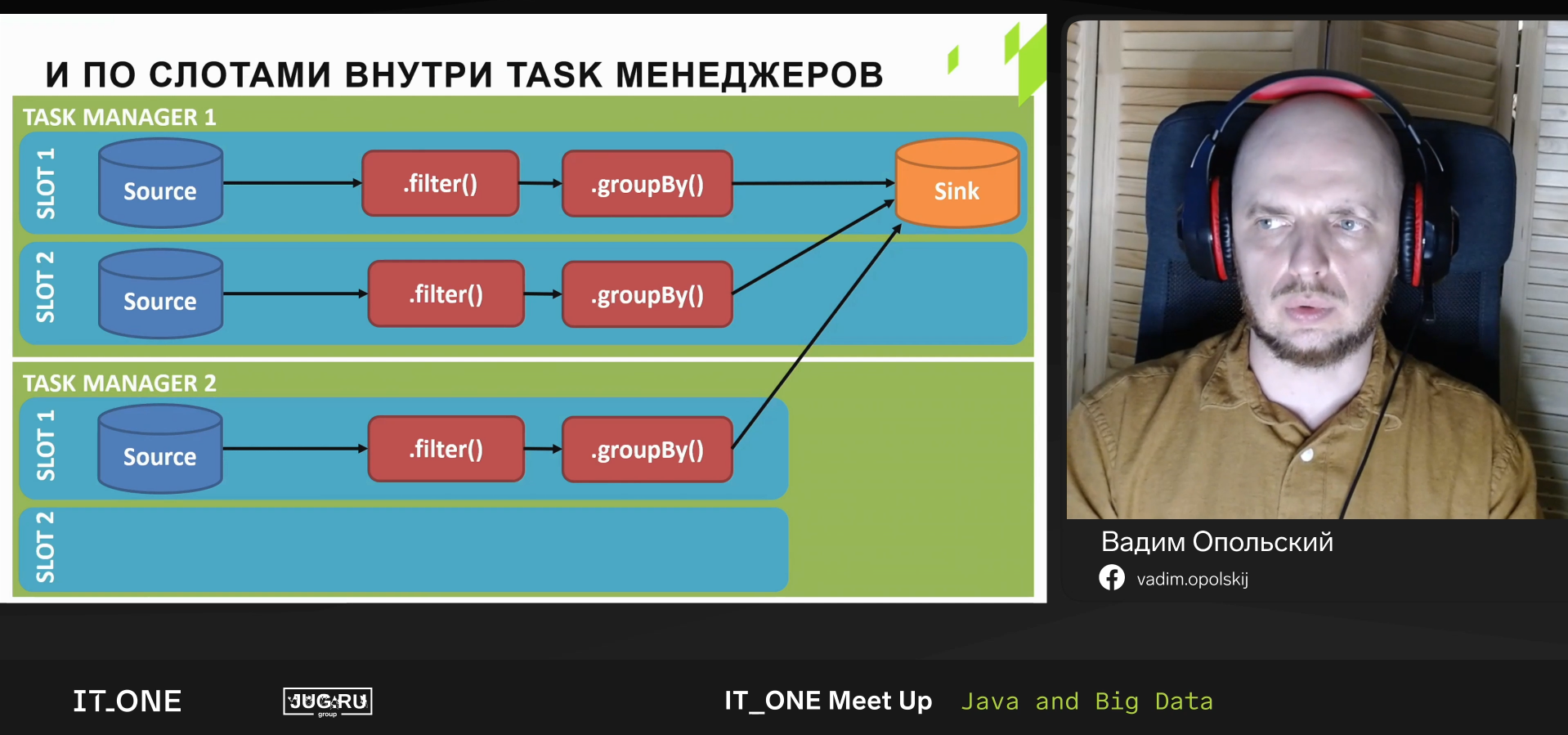
Flink works well in parallel mode. Throughput may be lower than in source - you have tools to monitor the lag and learn if you have to deal with the problem (lag > 0 = bad). Can configure alarm.
Bucketing sink -> Streaming file sink -> File sink - allows you to store several files in one file (to help Hadoop).
Can write to several data sources.
In conclusion:
Challenges:
- Inconsistent data flow
- Processors fail, data gets lost
- Too much data, too weak machines
- Throughput on the receiver is lower than on the source
- Uncontrollable data size on exit
…Solved by Flink:
- Akka Actors
- Self-restoration with no data losses
- Works parallelly
- Monitors lag in data
- Flexible config for receivers
Round table discussion
How to make sure that your data pipeline from logs to business charts and analytics won’t lie and won’t break anything? A problem with no apparent technical solution (can be solved only with proper communication between development teams, data engineers, and business analysts).
Data Quality might be one task, but the business might have different expectations.