Joker 2020. Days 1 & 2.
My synopsis
Spring: Your next Java microframework
Presented by Alexey Nesterov. First time presented in the Russian language.
Using Spring as micro-framework. Microframework: often is specifically designed for building the APIs for another service or application. In microframeworks, people typically seek ease of development, speed, simplicity, cloud-readiness (cloud-native).
Spring easy.
(…to develop)
Autoconfigs, profiles, etc. No Livereload? There is livereload for Spring! Spring Boot Dev Tools: livereload, works even remotely + tons of other features.
- Spring Boot Dev Tools
- Defaults, no template caching, debug logging
- Load global properties from ~/.config/spring-boot-devtools/
- Automatic reloading on classpath changes
- Automatic remote reloading
- LiveReload protocol
<Demo where Spring Boot app is launched inside a container, but using RemoteSpringApplication presenter tries to dynamically update an app from Idea>
Spring fast.
- Hints for speeding Spring Boot 2.3+ up
- Lazy beans initialization
- Lazy loading for repositories
- Unpack executable jar and provide Main class
- Use spring-context-indexer
- Functional beans and controllers
- No Actuator
- Reactive stack
- Spring boot is fast, but
- CPU might be a bottleneck
- different JVMs (like J9)
- Use of CDS
- Compile to native file with GraalVM
If still slow: profiling (Java flight recorder -> Java mission control), or include in actuator /actuator/startup.
Spring simple.
“Easy” = Spring “magic”, “Simple” = transparent.
You can “simplify” spring boot, but it might get harder in work.
Component scanning -> Functional beans
Route mapping -> Functional routing
Generated queries -> @Query / go away from JPA
Autoconfigurations -> Manual import
“I don’t need DI, I can describe everything in the main”
Functional Beans Registration
- In the beginning there was XML for context configuration
- Then @Annotations came to
replacehelp - Now it’s time for functions
Spring context = XML + Annotations + Functional Beans (everything works together).
<Demo: SpringApplicationBuilder, using initializers, creating beans with applicationContext.registerBean(...)>
- Functional routing:
- First appeared in WebFlux - WebFlux.fn;
- Is supported in WebMvc.fn;
- Is beautiful with Kotlin.
<Demo: using RouterFunction, route().GET("/foo", request -> { ... })>
Comments for demo: routing can be defined programmatically too now.
<Demo for spring data: demonstrate how even SQL requests might be configured programmatically, with Strings for SQL selects: full Spring application could be created without a single annotation, would still use Spring benefits like auto-wiring(?)>
Spring cloud-ready.
- Cloud-Native movement started with Spring Boot.
- Spring Cloud - Circuit Breakers, Configuration, Service registry, Load balancing, API Gateways;
- Even Serverless - Spring Cloud Function.
- Spring supports cloud platforms too:
- Kubernetes (liveness probe, readiness probe, volume mounted config directory trees, graceful shutdown)
- Cloud Foundry (Bindings, Buildpacs)
- AWS
- Alibaba
- and others
“…If you are writing Dockerfiles per hand - take a look at Java Memory Calculator project…”
Spring Boot can be used with GraalVM - to be compiled natively.
- From the discussion with experts:
- Spring dev tools reboots full application, if your Spring Security has some sort of in-memory sessions - those will be lost;
- Functional beans lifecycle - same lifecycle like with regular beans, the only difference - no reflection, only lambdas you defined;
- Bean post-processors - can be registered just like normal beans;
- Functional beans are a bit faster than regular beans;
How we did SQL in Hazelcast
Presented by Vladimir Ozerov.
Main principles of designing distributed SQL engines.
They had: predicate API (possibility to find data by predicate), in-memory indexes. Predicate API bad, because: might fail with OutOfMemory, limited functionality (how to do join?). Decided to migrate to SQL (duh!).
First versions: only select ... from ... where + index support.
Optimize queries based on Apache Calcite; have a protocol for distributed query execution, non-blocking cooperative parallelization model, basis for future improvements (join/sort/aggregate, compiling).
First analysis: optimizers are hard. Many use Apache Calcite - started with it. Apache Calcite: dynamic data management framework; contains: ANSI SQL parser, logical optimizer, runtime, JDBC.
Process of optimizing: SQL -> Optimizer -> Plan.
- Syntax analysis
- Semantic analysis
- Optimizing
Papers on optimizing: “Access Path Selection in a Relational Database Management System”, “The Cascades Framework for Query Optimization”.
<Skipped rest of presentation, since it’s not something I’d be working on any time soon>
Java Licensing Tips
Presented by Yurly Milyutin
Update from JDK_8_202 -> 203 = start paying money!
3 options:
- Stay with JDK_8_202
- Migrate to OpenJDK with a free license
- Internal audit, reduce number of licenses, pay the bills.
Server license for commercial use: $25 per processor (1-99 instances), might be lower, depending on the amount.
"Usage" = fact of installed JDK/JRE on your production servers.
(Even if you don’t run a single Java app on it yet)
Given: You have a server with 2 processor sockets, with x2 Intel Xeon E5-2680 v4 installed. Each processor has 14 physical cores, hyper-threading is on - for each physical core you have 2 logical cores.
Question: How many licenses “per processor” do you need?
Answer: consult lawyers, but here it’s 14 licenses: 28 per physical cores, multiplied by processor coefficient from a table (0.5) and rounded up.
Kubernetes / clouds - still pay. If JDK is installed for other Oracle product (Database, WebLogic…) - don’t need to pay for loicense, but other host apps ay not use this JDK for free.
User licenses: per concrete user, (1 user with 10 notebooks = 1 license, 5 users on one computer = 5 licenses).
Morale: read license agreements, think about company costs, migrate to OpenJDK, make internal audits to be ready for external ones.
Spring Boot “fat” JAR: Thin parts of a thick artifact
Presented by Vladimir Plizga (Владимир Плизга). Invited experts: Andrey Belyaev, Andrei Kogun. Presentation on Joker, author-provided presentation (including github).
First “fat” JARs: 1890, Moscow by Vasily Zvyozdochkin.
In Spring Boot since v1.0.
“Fat” JAR:
JVM: call `java -jar fat.jar`
↳ JarLauncher: `org.springframework.boot.loader`, in Manifest as Main-Class, "marks" whole archive by entry positions (1)
↳ Entry point - class with main(), in Manifest as Start-Class
↳ LaunchedUrl-ClassLoader (subclass of URLClassLoader, attached to main thread, called for every class (2))
↳ delegates to JarUrlConnection (subclass of URLStreamHandler), for URL's with prefix "jar"
↳ RandomAccessFile (from java.io)
(1) “Marking external archive”:
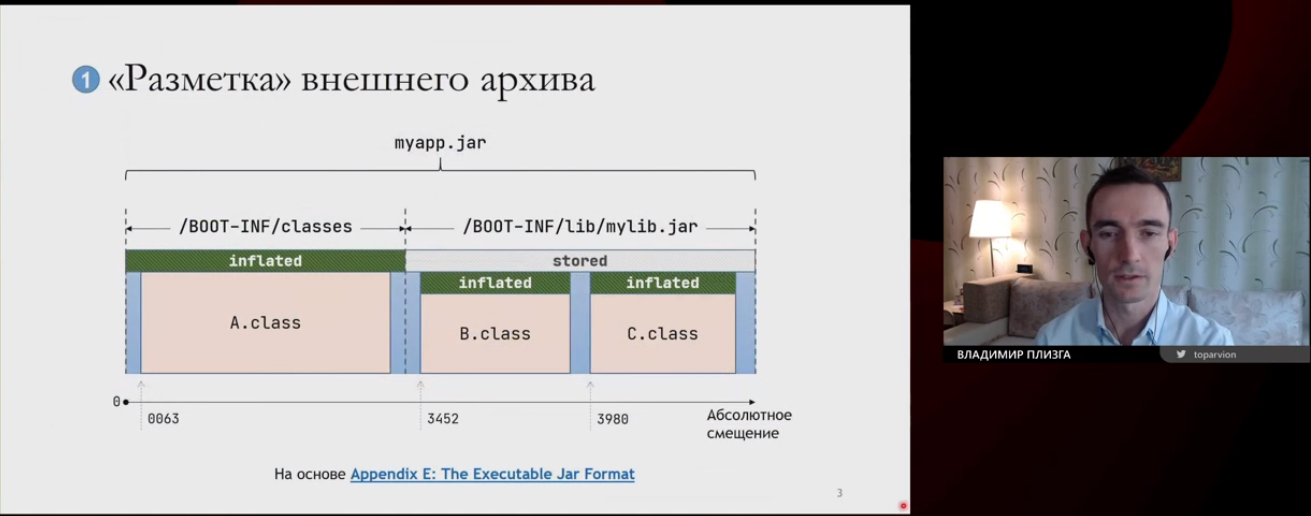 (Image from Vladimir Plizga’s presentation)
(Image from Vladimir Plizga’s presentation)
- (2) Loading classes from archives:
jar:file:/C:/bla/bla/fat.jar!BOOT-INF/lib/slf4j-api-1.7.30.jar!/org/slf4j/LoggerFactory.class - jar: - URL schema for Handler
- file:/C:/bla/bla/fat.jar - full path (URL) to external archive
- !/BOOT-INF/lib/slf4j-api-1.7.30.jar - path to internal archive
- !/org/slf4j/LoggerFactory.class - path to the end class
- “Fat” JAR:
- Internal archives are not compressed;
- Attach own subclass of URLClassLoader to main thread;
- Custom Handler for URL’s (
java.protocol.handler.pkgs); - Class loading basically works like reading from the external archive from the correct offset through
RandomAccessFile.
To debugging “fat” JAR loading:
- Download Spring Boot of correct version
- Set breakpoint on
org.springframework.boot.loader.JarLauncher#main - Run “fat” JAR with debuggier:
-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=*:5005 - Attach debugger from Spring Boot project
From the discussion with experts:
- It can go wrong
- Launching from IDEA differs with “fat” JAR
- Might lead to Class/Method not found exceptions if, for example, different versions of the same library are imported in one project
- “It works on my PC”-kind of bugs
=> Start testing “fat” JAR work during the development phase!
Potential problems with jshell, jdeps, jmint, java.util.logging (JUL) (+ it’s extensions like Oracle JDBC Diagnostic Driver).
Potential solutions: avoid using ClassLoader.getSystemClassLoader(), just unpack whole “fat” JAR.
Question from an expert: how difficult would it be to migrate from the application server to “fat” JAR?
JarLauncher has a “twin brother” WarLauncher. WAR can be launcher as java -jar fat.war, demands explicit declaration of provided dependencies, creates a different set of tasks in Gradle, has a bit different internal directory tree (WEB-INF/lib, WEB-INF/lib-provided). “Fat” WAR limitations: can’t have layers.ids, doesn’t work with WebFlux, but it can be used for gradual migration to Spring Boot (while still deploying to standalone Tomcat/Liberty or any other application server), for compatibility with some PaaS systems, or to work from both from servlet-container and autonomously (but think twice if you really need that!)
Question from an expert: what about docker and microservices?
Docker builds images from ordered layers - each next layer is a diff from the previous one, is described by hash, hashes match => do nothing.
Hashes not match - rebuild this and every next layer. Spring Boot from v2.3 offers new mode -Djarmode=layertools => allows writing “fat” archive as thin layers, works with Maven/Gradle plugins. Reads created file in /BOOT-INF/layers.idx.
Running java -Djarmode=layertools -jar fat.jar list displays list of layers. By default (?) they go in such order: dependencies, spring-boot-loader, snapshot-dependencies, generated, application. Gradle DSL (in Spring Boot 2.3 - have to turn it on, in 2.4 - on by default):
bootJar {
archiveFileName = 'fat.jar'
manifest { ... }
layered {
application {
...
intoLayer("spring-boot-loader") {
include "org/springbootloader/**" //everything from this package
}
...
intoLayer("application") // everything else
}
dependencies {
...
}
layerOrder = ['dependencies', 'spring-boot-loader', ...]
}
}
↳ creates layers.idx file
Dockerfile-layers:
FROM .../openjdk-alpine:11 as builder
WORKDIR application
COPY fat.jar fat.jar
RUN java -Djarmode=layertools -jar fat.jar extract
...
FROM ...openjdk-alpine:11
WORKDIR application
COPY --from=builder application/dependencies/ ./
COPY --from=builder application/spring-boot-loader/ ./
...
ENTRYPOINT ["java", "org.springframework.boot.loader.JarLauncher"]
Why JarLauncher? Even with already extracted artifact, it still figures manifest version from the JAR, does some more “magic”.
dive utility for analyzing layers.
Layertools: full control over the build, small image size. Cons: complicated Dockerfile, too many manual actions.
Question from an expert: how do we get a “make it good” button, to remove manual actions from the previous approach?
Buildpack - set of actions for building and launching apps in containers. Detection - tests iteslf for applicability, contains no images, the idea came from Heroku & CloudFoundry, now in CNF as well.
Builder - image, including buildpacks and other images for launching the application.
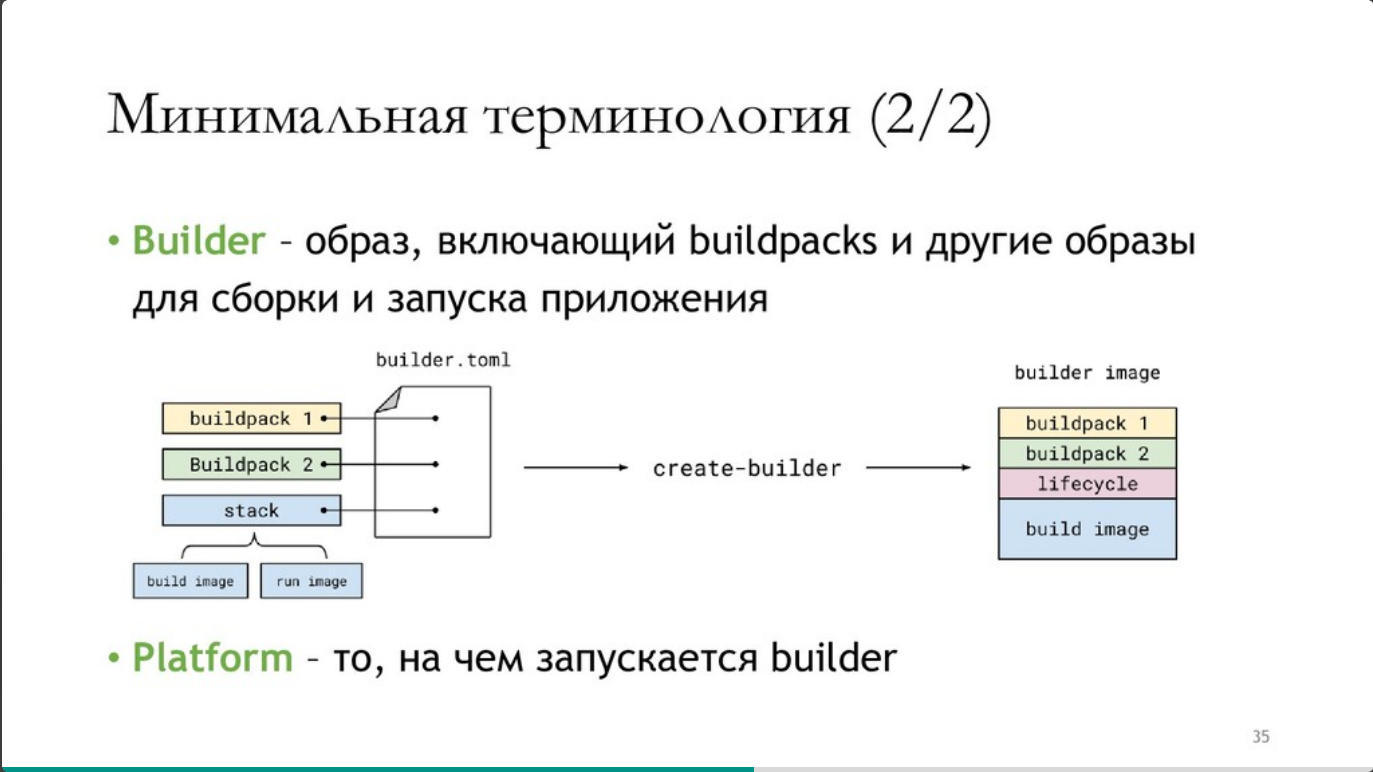 (Image from Vladimir Plizga’s presentation)
(Image from Vladimir Plizga’s presentation)
Starting from v2.3 Spring Boot we can build images via buildpacks (no more Dockerfile, still need Docker daemon). Spring Boot Maven/Gradle plugins are a platform, using builders and buildpacks from Paketo.io (including Java Buildpacks, can be manually adjusted).
gradle :bootBuildImage For manual control: gradlew bootBuildImage --imageName=fatjar/oci
Buildpacks: + no more docker file, lots of out-of-box functionality, - massive image size, dependant on docker daemon.
Alternative tools: Google Jib. Can work as a Maven/Gradle plugin, can build images w/o Docker Daemon, supports layers. gradle jib/jibBuildTar/jibDockerBuild. For controlling layer structure, need to use another plugin for this plugin.
Both Jib and Buildpacs use everything to make artifacts reproducable, for example, build dates are set to the start of the Unix epoch.
Jib. Pros: no need for docker daemon / Dockerfile, works for any Java app; Cons: does not regards Spring Boot specifics, hard to manage layers.
Other solutions include fabric8io, Spotify, Palantir, bmuschko, Google Jib, Cloud Foundry, Spring Boot OCI Plugins…
Presenters’ recommendations: if you need maximal control and simplicity of an image - go Layertools; if you need to “just make it magically work” - go Buildpacks, can’t use Docker, or Spring Boot 2.3+ - go Jib.
Alternative solution: just unpack fat JAR, but it’s easier to track manifest metadata.
Mentioned Spring Boot Admin for tracking all the Spring Boot apps.
- Conclusion:
- start checking class-path in IDE;
- update to Spring Boot 2.3+;
- unpack JAR in target environment;
- Run via JarLauncher (not via Main-Class);
- Consider Cloud Matove Buildpacks.
- Links:
- https://spring.io/blog/2020/08/14/creating-efficient-docker-images-with-spring-boot-2-3
- https://youtu.be/WL7U-yGfUXA
- https://reflectoring.io/spring-boot-docker/
- https://www.profit4cloud.nl/blog/building-containers-with-spring-boot-2-3/
Working with in-memory data sharding with a flavor of Spring Data
Presented by Alexey Kuzin.
Typical information exchange flow within the system:
Web Form <-> Request objec <-> Java Object <-> Request object <-> Database format.
Typical code with JPA EntityManager: @Repository, @PersistenceContext, …
The Growth problem - maintaining the system throughput, more data - more transactions, data model evolves, need to maintain the same SLA or make the response times faster.
Solutions:
- Optimizing the communication with DB and/or vertical scaling
- Changing the data model and/or horizontal scaling
- Changing the datastore technology
- A combination of any of the above methods
(2, 3, 4 - data migration, code refactoring)
Scaling DB out: sharding. Vertical partitioning (split by columns), horizontal partitioning (split by rows). Sharding complexities: even writing declarative SQL queries we need to know how it will be performed. Users must access distributed database seamlessly as a non-distributed one.
- Spring Data: a programming model:
- Templates (front for all operations one can do with DB)
- Repositories (front for CRUD operations)
- Object mapping (data conversion from raw data into POJO)
Repositories: @Repository - the old way. A special case of @Component, provides special Exception translation.
Interfaces: Repository<T, ID>, CrudRepository<T, ID>, PagingAndSortingRepository<T, ID>, mark interfaces as candidates for proxy bean creation, @RepositoryDefinition for the completely custom interface.
@EnableXXXRepositories - configures repositories, enables constructing of proxy beans for corresponding repositories, configures where to scan entities for the corresponding repositories.
- EnableXXXRepositories provides:
- List of packages for entities
- Basic entity interface which is supported for proxying
- Query lookup strategy
- Repository factory and factory bean classes
- Where named queries are stored
- Custom properties
Proxy beans are created lazily, proxy beans for repositories use default repository implementations.

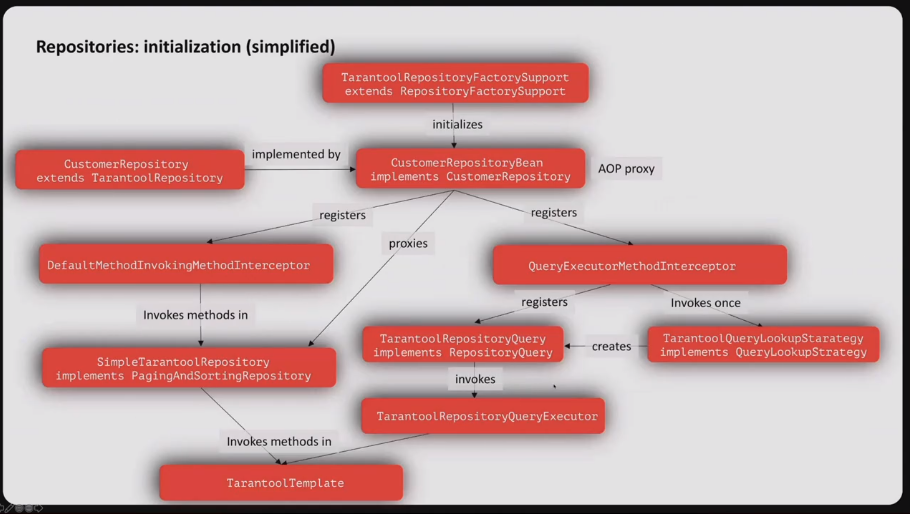 (Images from Alexey Kuzin’s presentation)
(Images from Alexey Kuzin’s presentation)
Entities: custom converters @ReadingConverter/@WritingConverter, implements Converter<Number, LocalDateTime>.